Integrating OpenTelemetry for Data Collection
Any Observability solution requires a means of collecting and exporting logs and traces. For this purpose, ClickHouse recommends the OpenTelemetry (OTel) project.
"OpenTelemetry is an Observability framework and toolkit designed to create and manage telemetry data such as traces, metrics, and logs."
Unlike ClickHouse or Prometheus, OpenTelemetry is not an observability backend and rather focuses on the generation, collection, management, and export of telemetry data. While the initial goal of OpenTelemetry was to allow users to instrument their applications or systems using language-specific SDKs easily, it has expanded to include the collection of logs through the OpenTelemetry collector - an agent or proxy that receives, processes, and exports telemetry data.
ClickHouse relevant components
Open Telemetry consists of a number of components. As well as providing a data and API specification, standardized protocol, and naming conventions for fields/columns, OTeL provides two capabilities which fundamental to building an Observability solution with ClickHouse:
- The OpenTelemetry Collector is a proxy that receives, processes, and exports telemetry data. A ClickHouse-powered solution uses this component for both log collection and event processing prior to batching and inserting.
- Language SDKs that implement the specification, APIs, and export of telemetry data. These SDKs effectively ensure traces are correctly recorded within an application's code, generating constituent spans and ensuring context is propagated across services through metadata - thus formulating distributed traces and ensuring spans can be correlated. These SDKs are complemented by an ecosystem that automatically implements common libraries and frameworks, thus meaning the user is not required to change their code and obtains out-of-the-box instrumentation.
A ClickHouse-powered Observability solution exploits both of these tools.
Distributions
The OpenTelemetry collector has a number of distributions. The filelog receiver along with the ClickHouse exporter, required for a ClickHouse solution, is only present in the OpenTelemetry Collector Contrib Distro.
This distribution contains many components and allows users to experiment with various configurations. However, when running in production, it is recommended to limit the collector to contain only the components necessary for an environment. Some reasons to do this:
- Reduce the size of the collector, reducing deployment times for the collector
- Improve the security of the collector by reducing the available attack surface area
Building a custom collector can be achieved using the OpenTelemetry Collector Builder.
Ingesting data with OTel
Collector deployment roles
In order to collect logs and insert them into ClickHouse, we recommend using the OpenTelemetry Collector. The OpenTelemetry Collector can be deployed in two principal roles:
- Agent - Agent instances collect data at the edge e.g. on servers or on Kubernetes nodes, or receive events directly from applications — instrumented with an OpenTelemetry SDK. In the latter case, the agent instance runs with the application or on the same host as the application (such as a sidecar or a DaemonSet). Agents can either send their data directly to ClickHouse or to a gateway instance. In the former case, this is referred to as Agent deployment pattern.
- Gateway - Gateway instances provide a standalone service (for example, a deployment in Kubernetes), typically per cluster, per data center, or per region. These receive events from applications (or other collectors as agents) via a single OTLP endpoint. Typically, a set of gateway instances are deployed, with an out-of-the-box load balancer used to distribute the load amongst them. If all agents and applications send their signals to this single endpoint, it is often referred to as a Gateway deployment pattern.
Below we assume a simple agent collector, sending its events directly to ClickHouse. See "Scaling with Gateways" for further details on using gateways and when they are applicable.
Collecting logs
The principal advantage of using a collector is it allows your services to offload data quickly, leaving the Collector to take care of additional handling like retries, batching, encryption or even sensitive data filtering.
The Collector uses the terms receiver, processor, and exporter for its three main processing stages. Receivers are used for data collection and can either be pull or push-based. Processors provide the ability to perform transformations and enrichment of messages. Exporters are responsible for sending the data to a downstream service. While this service can, in theory, be another collector, we assume all data is sent directly to ClickHouse for the initial discussion below.
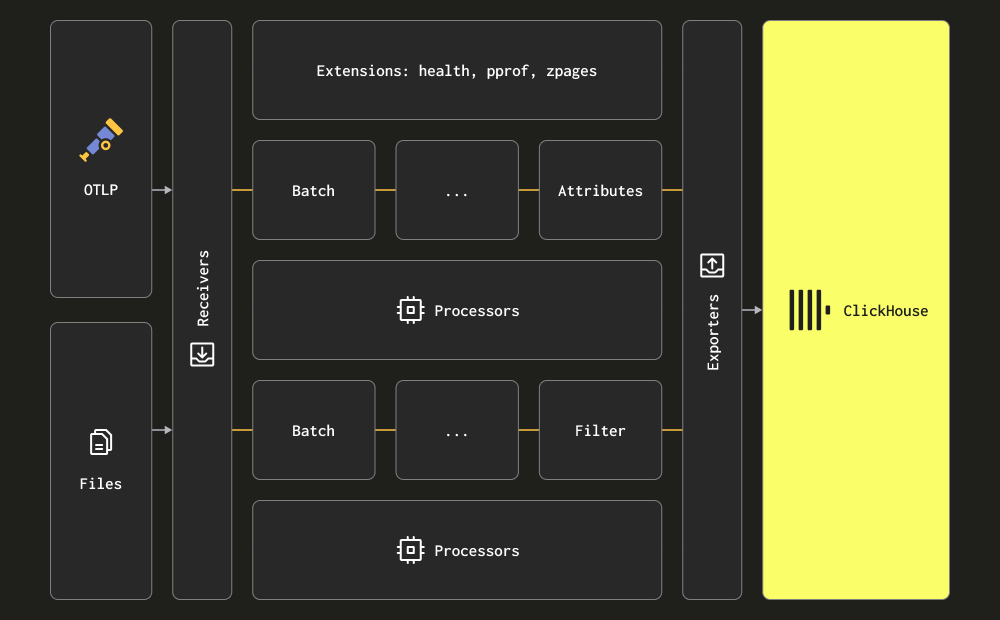
We recommend users familiarize themselves with the full set of receivers, processors and exporters.
The collector provides two principal receivers for collecting logs:
Via OTLP - In this case, logs are sent (push) directly to the collector from OpenTelemetry SDKs via the OTLP protocol. The OpenTelemetry demo employs this approach, with the OTLP exporters in each language assuming a local collector endpoint. The collector must be configured with the OTLP receiver in this case —see the above demo for a configuration. The advantage of this approach is that log data will automatically contain Trace Ids, allowing users to later identify the traces for a specific log and vice versa.
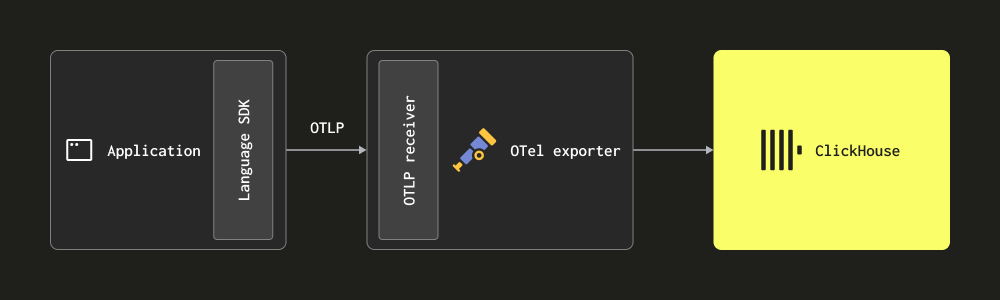
This approach requires users to instrument their code with their appropriate language SDK.
- Scraping via Filelog receiver - This receiver tails files on disk and formulates log messages, sending these to ClickHouse. This receiver handles complex tasks such as detecting multi-line messages, handling log rollovers, checkpointing for robustness to restart, and extracting structure. This receiver is additionally able to tail Docker and Kubernetes container logs, deployable as a helm chart, extracting the structure from these and enriching them with the pod details.
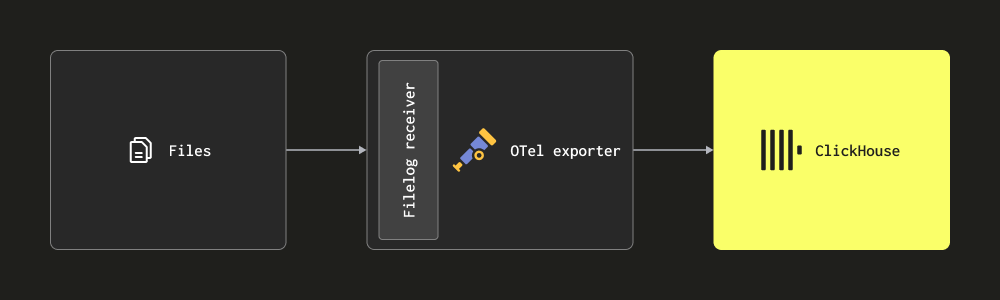
Most deployments will use a combination of the above. We recommend users read the collector documentation and familiarize themselves with the basic concepts, along with the configuration structure and installation methods.
Tip: otelbin.io is useful to validate and visualize configurations.
Structured vs Unstructured
Logs can either be structured or unstructured.
A structured log will employ a data format such as JSON, defining metadata fields such as http code and source IP address.
{
"remote_addr":"54.36.149.41",
"remote_user":"-","run_time":"0","time_local":"2019-01-22 00:26:14.000","request_type":"GET",
"request_path":"\/filter\/27|13 ,27| 5 ,p53","request_protocol":"HTTP\/1.1",
"status":"200",
"size":"30577",
"referer":"-",
"user_agent":"Mozilla\/5.0 (compatible; AhrefsBot\/6.1; +http:\/\/ahrefs.com\/robot\/)"
}
Unstructured logs, while also typically having some inherent structure extractable through a regex pattern, will represent the log as purely a string.
54.36.149.41 - - [22/Jan/2019:03:56:14 +0330] "GET
/filter/27|13%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,27|%DA%A9%D9%85%D8%AA%D8%B1%20%D8%A7%D8%B2%205%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,p53 HTTP/1.1" 200 30577 "-" "Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)" "-"
We recommend users employ structured logging and log in JSON (i.e. ndjson) where possible. This will simplify the required processing of logs later, either prior to sending to ClickHouse with Collector processors or at insert time using materialized views. Structured logs will ultimately save on later processing resources, reducing the required CPU in your ClickHouse solution.
Example
For example purposes, we provide a structured (JSON) and unstructured logging dataset, each with approximately 10m rows, available at the following links:
We use the structured dataset for the example below. Ensure this file is downloaded and extracted to reproduce the following examples.
The following represents a simple configuration for the OTel Collector which reads these files on disk, using the filelog receiver, and outputs the resulting messages to stdout. We use the json_parser operator since our logs are structured. Modify the path to the access-structured.log file.
The below example extracts the timestamp from the log. This requires the use of the
json_parseroperator, which converts the entire log line to a JSON string, placing the result inLogAttributes. This can be computationally expensive and can be done more efficiently in ClickHouse - see "Extracting structure with SQL". An equivalent unstructured example, which uses theregex_parserto achieve this, can be found here.
receivers:
filelog:
include:
- /opt/data/logs/access-structured.log
start_at: beginning
operators:
- type: json_parser
timestamp:
parse_from: attributes.time_local
layout: '%Y-%m-%d %H:%M:%S'
processors:
batch:
timeout: 5s
send_batch_size: 1
exporters:
logging:
loglevel: debug
service:
pipelines:
logs:
receivers: [filelog]
processors: [batch]
exporters: [logging]
Users can follow the official instructions to install the collector locally. Importantly, ensure the instructions are modified to use the contrib distribution (which contains the filelog receiver) e.g. instead of otelcol_0.102.1_darwin_arm64.tar.gz users would download otelcol-contrib_0.102.1_darwin_arm64.tar.gz. Releases can be found here.
Once installed, the OTel Collector can be run with the following commands:
./otelcol-contrib --config config-logs.yaml
Assuming the use of the structured logs, messages will take the following form on the output:
LogRecord #98
ObservedTimestamp: 2024-06-19 13:21:16.414259 +0000 UTC
Timestamp: 2019-01-22 01:12:53 +0000 UTC
SeverityText:
SeverityNumber: Unspecified(0)
Body: Str({"remote_addr":"66.249.66.195","remote_user":"-","run_time":"0","time_local":"2019-01-22 01:12:53.000","request_type":"GET","request_path":"\/product\/7564","request_protocol":"HTTP\/1.1","status":"301","size":"178","referer":"-","user_agent":"Mozilla\/5.0 (Linux; Android 6.0.1; Nexus 5X Build\/MMB29P) AppleWebKit\/537.36 (KHTML, like Gecko) Chrome\/41.0.2272.96 Mobile Safari\/537.36 (compatible; Googlebot\/2.1; +http:\/\/www.google.com\/bot.html)"})
Attributes:
-> remote_user: Str(-)
-> request_protocol: Str(HTTP/1.1)
-> time_local: Str(2019-01-22 01:12:53.000)
-> user_agent: Str(Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html))
-> log.file.name: Str(access.log)
-> status: Str(301)
-> size: Str(178)
-> referer: Str(-)
-> remote_addr: Str(66.249.66.195)
-> request_type: Str(GET)
-> request_path: Str(/product/7564)
-> run_time: Str(0)
Trace ID:
Span ID:
Flags: 0
The above represents a single log message as produced by the OTel collector. We ingest these same messages into ClickHouse in later sections.
The full schema of log messages, along with additional columns which may be present if using other receivers, is maintained here. We strongly recommend users familiarize themselves with this schema.
The key here is that the log line itself is held as a string within the Body field but the JSON has been auto-extracted to the Attributes field thanks to the json_parser. This same operator has been used to extract the timestamp to the appropriate Timestamp column. See recommendations on processing logs with Otel see "Processing".
Operators are the most basic unit of log processing. Each operator fulfills a single responsibility, such as reading lines from a file or parsing JSON from a field. Operators are then chained together in a pipeline to achieve the desired result.
The above messages don't have a TraceID or SpanID field. If present, e.g. in cases where users are implementing distributed tracing, these could be extracted from the JSON using the same techniques shown above.
For users needing to collect local or kubernetes log files, we recommend users become familiar with the configuration options available for the filelog receiver and how offsets and multiline log parsing is handled.
Collecting Kubernetes Logs
For the collection of Kubernetes logs, we recommend the Open Telemetry documentation guide. The Kubernetes Attributes Processor is recommended for enriching logs and metrics with pod metadata. This can potentially produce dynamic metadata e.g. labels, stored in the column ResourceAttributes. ClickHouse currently uses the type Map(String, String) for this column. See "Using Maps" and "Extracting from maps" for further details on handling and optimizing this type.
Collecting traces
For users looking to instrument their code and collect traces, we recommend following the official OTel documentation.
In order to deliver events to ClickHouse, users will need to deploy an OTel collector to receive trace events over the OTLP protocol via the appropriate receiver. The OpenTelemetry demo provides an example of instrumenting each supported language and sending events to a collector. An example of an appropriate collector configuration which outputs events to stdout is shown below:
Example
Since traces must be received via OTLP we use the telemetrygen tool for generating trace data. Follow the instructions here for installation.
The following configuration receives trace events on an OTLP receiver before sending them to stdout.
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
processors:
batch:
timeout: 1s
exporters:
logging:
loglevel: debug
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [logging]
Run this configuration via:
./otelcol-contrib --config config-traces.yaml
Send trace events to the collector via telemetrygen:
$GOBIN/telemetrygen traces --otlp-insecure --traces 300
This will result in trace messages similar to the example below, being output to stdout:
Span #86
Trace ID : 1bb5cdd2c9df5f0da320ca22045c60d9
Parent ID : ce129e5c2dd51378
ID : fbb14077b5e149a0
Name : okey-dokey-0
Kind : Server
Start time : 2024-06-19 18:03:41.603868 +0000 UTC
End time : 2024-06-19 18:03:41.603991 +0000 UTC
Status code : Unset
Status message :
Attributes:
-> net.peer.ip: Str(1.2.3.4)
-> peer.service: Str(telemetrygen-client)
The above represents a single trace message as produced by the OTel collector. We ingest these same messages into ClickHouse in later sections.
The full schema of trace messages is maintained here. We strongly recommend users familiarize themselves with this schema.
Processing - filtering, transforming and enriching
As demonstrated in the earlier example of setting the timestamp for a log event, users will invariably want to filter, transform, and enrich event messages. This can be achieved using a number of capabilities in Open Telemetry:
Processors - Processors take the data collected by receivers and modify or transform it before sending it to the exporters. Processors are applied in the order as configured in the
processorssection of the collector configuration. These are optional, but the minimal set is typically recommended. When using an OTeL collector with ClickHouse, we recommend limiting processors to:- A memory_limiter is used to prevent out of memory situations on the collector. See "Estimating Resources" for recommendations.
- Any processor that does enrichment based on context. For example, the Kubernetes Attributes Processor allows the automatic setting of spans, metrics, and logs resource attributes with k8s metadata e.g. enriching events with their source pod id.
- Tail or head sampling if required for traces.
- Basic filtering - Dropping events that are not required if this cannot be done via operator (see below).
- Batching - essential when working with ClickHouse to ensure data is sent in batches. See Exporting to ClickHouse.
Operators - Operators provide the most basic unit of processing available at the receiver. Basic parsing is supported, allowing fields such as the Severity and Timestamp to be set. JSON and regex parsing is supported here along with event filtering and basic transformations. We recommend performing event filtering here.
We recommend users avoid doing excessive event processing using operators or transform processors. These can incur considerable memory and CPU overhead, especially JSON parsing. It is possible to do all processing in ClickHouse at insert time with materialized views and columns with some exceptions - specifically, context-aware enrichment e.g. adding of k8s metadata. For more details see "Extracting structure with SQL".
If processing is done using the OTel collector, we recommend doing transformations at gateway instances and minimizing any work done at agent instances. This will ensure the resources required by agents at the edge, running on servers, are as minimal as possible. Typically, we see users only performing filtering (to minimize unnecessary network usage), timestamp setting (via operators), and enrichment, which requires context in agents. For example, if gateway instances reside in a different Kubernetes cluster, k8s enrichment will need to occur in the agent.
Example
The following configuration shows collection of the unstructured log file. Note the use of operators to extract structure from the log lines (regex_parser) and filter events, along with a processor to batch events and limit memory usage.
config-unstructured-logs-with-processor.yaml
receivers:
filelog:
include:
- /opt/data/logs/access-unstructured.log
start_at: beginning
operators:
- type: regex_parser
regex: '^(?P<ip>[\d.]+)\s+-\s+-\s+\[(?P<timestamp>[^\]]+)\]\s+"(?P<method>[A-Z]+)\s+(?P<url>[^\s]+)\s+HTTP/[^\s]+"\s+(?P<status>\d+)\s+(?P<size>\d+)\s+"(?P<referrer>[^"]*)"\s+"(?P<user_agent>[^"]*)"'
timestamp:
parse_from: attributes.timestamp
layout: '%d/%b/%Y:%H:%M:%S %z'
#22/Jan/2019:03:56:14 +0330
processors:
batch:
timeout: 1s
send_batch_size: 100
memory_limiter:
check_interval: 1s
limit_mib: 2048
spike_limit_mib: 256
exporters:
logging:
loglevel: debug
service:
pipelines:
logs:
receivers: [filelog]
processors: [batch, memory_limiter]
exporters: [logging]
./otelcol-contrib --config config-unstructured-logs-with-processor.yaml
Exporting to ClickHouse
Exporters send data to one or more backends or destinations. Exporters can be pull or push-based. In order to send events to ClickHouse, users will need to use the push-based ClickHouse exporter.
The ClickHouse exporter is part of the OpenTelemetry Collector Contrib, not the core distribution. Users can either use the contrib distribution or build their own collector.
A full configuration file is shown below.
receivers:
filelog:
include:
- /opt/data/logs/access-structured.log
start_at: beginning
operators:
- type: json_parser
timestamp:
parse_from: attributes.time_local
layout: '%Y-%m-%d %H:%M:%S'
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
processors:
batch:
timeout: 5s
send_batch_size: 5000
exporters:
clickhouse:
endpoint: tcp://localhost:9000?dial_timeout=10s&compress=lz4&async_insert=1
# ttl: 72h
traces_table_name: otel_traces
logs_table_name: otel_logs
create_schema: true
timeout: 5s
database: default
sending_queue:
queue_size: 1000
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
service:
pipelines:
logs:
receivers: [filelog]
processors: [batch]
exporters: [clickhouse]
traces:
receivers: [otlp]
processors: [batch]
exporters: [clickhouse]
Note the following key settings:
- pipelines - The above configuration highlights the use of pipelines, consisting of a set of receivers, processors and exporters with one for logs and traces.
- endpoint - Communication with ClickHouse is configured via the
endpointparameter. The connection stringtcp://localhost:9000?dial_timeout=10s&compress=lz4&async_insert=1causes communication to occur over TCP. If users prefer HTTP for traffic-switching reasons, modify this connection string as described here. Full connection details, with the ability to specify a username and password within this connection string, are described here.
Important: Note the above connection string enables both compression (lz4) as well as asynchronous inserts. We recommend both are always enabled. See "Batching" for further details on asynchronous inserts. Compression should always be specified and will not by default be enabled by default on older versions of the exporter.
- ttl - the value here determines how long data is retained. Further details in "Managing data". This should be specified as a time unit in hours e.g. 72h. We disable TTL in the example below since our data is from 2019 and will be removed by ClickHouse immediately if inserted.
- traces_table_name and logs_table_name - determines the name of the logs and traces table.
- create_schema - determines if tables are created with the default schemas on startup. Defaults to true for getting started. Users should set it to false and define their own schema.
- database - target database.
- retry_on_failure - settings to determine whether failed batches should be tried.
- batch - a batch processor ensures events are sent as batches. We recommend a value of around 5000 with a timeout of 5s. Whichever of these is reached first will initiate a batch to be flushed to the exporter. Lowering these values will mean a lower latency pipeline with data available for querying sooner, at the expense of more connections and batches sent to ClickHouse. This is not recommended if users are not using [asynchronous inserts](asynchronous inserts) as it may cause issues with too many parts in ClickHouse. Conversely, if users are using asynchronous inserts these availability data for querying will also be dependent on asynchronous insert settings - although data will still be flushed from the connector sooner. See "Batching" for more details.
- sending_queue - controls the size of the sending queue. Each item in the queue contains a batch. If this queue is exceeded e.g. due to ClickHouse being unreachable but events continue to arrive, batches will be dropped. See "Handling backpressure" for more details.
Assuming users have extracted the structured log file and have a local instance of ClickHouse running (with default authentication), users can run this configuration via the command:
./otelcol-contrib --config clickhouse-config.yaml
To send trace data to this collector, run the following command using the telemetrygen tool:
$GOBIN/telemetrygen traces --otlp-insecure --traces 300
Once running, confirm log events are present with a simple query:
SELECT *
FROM otel_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
Timestamp: 2019-01-22 06:46:14.000000000
TraceId:
SpanId:
TraceFlags: 0
SeverityText:
SeverityNumber: 0
ServiceName:
Body: {"remote_addr":"109.230.70.66","remote_user":"-","run_time":"0","time_local":"2019-01-22 06:46:14.000","request_type":"GET","request_path":"\/image\/61884\/productModel\/150x150","request_protocol":"HTTP\/1.1","status":"200","size":"1684","referer":"https:\/\/www.zanbil.ir\/filter\/p3%2Cb2","user_agent":"Mozilla\/5.0 (Windows NT 6.1; Win64; x64; rv:64.0) Gecko\/20100101 Firefox\/64.0"}
ResourceSchemaUrl:
ResourceAttributes: {}
ScopeSchemaUrl:
ScopeName:
ScopeVersion:
ScopeAttributes: {}
LogAttributes: {'referer':'https://www.zanbil.ir/filter/p3%2Cb2','log.file.name':'access-structured.log','run_time':'0','remote_user':'-','request_protocol':'HTTP/1.1','size':'1684','user_agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0','remote_addr':'109.230.70.66','request_path':'/image/61884/productModel/150x150','status':'200','time_local':'2019-01-22 06:46:14.000','request_type':'GET'}
1 row in set. Elapsed: 0.012 sec. Processed 5.04 thousand rows, 4.62 MB (414.14 thousand rows/s., 379.48 MB/s.)
Peak memory usage: 5.41 MiB.
Likewise, for trace events, users can check the `otel_traces` table:
SELECT *
FROM otel_traces
LIMIT 1
FORMAT Vertical
Row 1:
──────
Timestamp: 2024-06-20 11:36:41.181398000
TraceId: 00bba81fbd38a242ebb0c81a8ab85d8f
SpanId: beef91a2c8685ace
ParentSpanId:
TraceState:
SpanName: lets-go
SpanKind: SPAN_KIND_CLIENT
ServiceName: telemetrygen
ResourceAttributes: {'service.name':'telemetrygen'}
ScopeName: telemetrygen
ScopeVersion:
SpanAttributes: {'peer.service':'telemetrygen-server','net.peer.ip':'1.2.3.4'}
Duration: 123000
StatusCode: STATUS_CODE_UNSET
StatusMessage:
Events.Timestamp: []
Events.Name: []
Events.Attributes: []
Links.TraceId: []
Links.SpanId: []
Links.TraceState: []
Links.Attributes: []
Out of the box schema
By default, the ClickHouse exporter creates a target log table for both logs and traces. This can be disabled via the setting create_schema. Furthermore, the names for both the logs and traces table can be modified from their defaults of otel_logs and otel_traces via the settings noted above.
In the schemas below we assume TTL has been enabled as 72h.
The default schema for logs is shown below (otelcol-contrib v0.102.1):
CREATE TABLE default.otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_scope_attr_key mapKeys(ScopeAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_scope_attr_value mapValues(ScopeAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_log_attr_key mapKeys(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_log_attr_value mapValues(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_body Body TYPE tokenbf_v1(32768, 3, 0) GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId)
TTL toDateTime(Timestamp) + toIntervalDay(3)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1
The columns here correlate with the OTel official specification for logs documented here.
A few important notes on this schema:
- By default the table is partitioned by date via
PARTITION BY toDate(Timestamp). This makes it efficient to drop data that expires. - The TTL is set via
TTL toDateTime(Timestamp) + toIntervalDay(3)and corresponds to the value set in the collector configuration.ttl_only_drop_parts=1means only whole parts are dropped when all the contained rows have expired. This is more efficient than dropping rows within parts, which incurs an expensive delete. We recommend this always be set. See "Data management with TTL" for more details. - The table uses the classic
MergeTreeengine. This is recommended for logs and traces and should not need to be changed. - The table is ordered by
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId). This means queries will be optimized for filters on ServiceName, SeverityText, Timestamp and TraceId - earlier columns in the list will filter faster than later ones e.g. filtering by ServiceName will be significantly faster than filtering by TraceId. Users should modify this ordering according to their expected access patterns - see "Choosing a primary key". - The above schema applies
ZSTD(1)to columns. This offers the best compression for logs. Users can increase the ZSTD compression level (1 above) for better compression, although this is rarely beneficial. Increasing this value will incur greater CPU overhead at insert time (during compression), although decompression (and thus queries) should remain comparable. See here for further details. Additional delta encoding is applied to the Timestamp with the aim of reducing its size on disk. - Note how
ResourceAttributes,LogAttributesandScopeAttributesare maps. Users should familiarize themselves with the difference between these. For how to access these maps and optimize accessing keys within them, see "Using maps". - Most other types here e.g.
ServiceNameas LowCardinality, are optimized. Note the Body, although JSON in our example logs, is stored as a String. - Bloom filters are applied to map keys and values, as well as the Body column. These aim to improve query times on accessing these columns but are typically not required. See "Secondary/Data skipping indices" below.
CREATE TABLE default.otel_traces
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`ParentSpanId` String CODEC(ZSTD(1)),
`TraceState` String CODEC(ZSTD(1)),
`SpanName` LowCardinality(String) CODEC(ZSTD(1)),
`SpanKind` LowCardinality(String) CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`SpanAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`Duration` Int64 CODEC(ZSTD(1)),
`StatusCode` LowCardinality(String) CODEC(ZSTD(1)),
`StatusMessage` String CODEC(ZSTD(1)),
`Events.Timestamp` Array(DateTime64(9)) CODEC(ZSTD(1)),
`Events.Name` Array(LowCardinality(String)) CODEC(ZSTD(1)),
`Events.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)),
`Links.TraceId` Array(String) CODEC(ZSTD(1)),
`Links.SpanId` Array(String) CODEC(ZSTD(1)),
`Links.TraceState` Array(String) CODEC(ZSTD(1)),
`Links.Attributes` Array(Map(LowCardinality(String), String)) CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_key mapKeys(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_span_attr_value mapValues(SpanAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_duration Duration TYPE minmax GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SpanName, toUnixTimestamp(Timestamp), TraceId)
TTL toDateTime(Timestamp) + toIntervalDay(3)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1
Again, this will correlate with the columns OTel official specification for traces documented here. The schema here employs many of the same settings as the above logs schema with additional Link columns specific to spans.
We recommend users disable auto schema creation and create their tables manually. This allows modification of the primary and secondary keys, as well as the opportunity to introduce additional columns for optimizing query performance. For further details see "Schema design".
Optimizing inserts
In order to achieve high insert performance while obtaining strong consistency guarantees, users should adhere to simple rules when inserting Observability data into ClickHouse via the collector. With the correct configuration of the OTel collector, the following rules should be straightforward to follow. This also avoids common issues users encounter when using ClickHouse for the first time.
Batching
By default, each insert sent to ClickHouse causes ClickHouse to immediately create a part of storage containing the data from the insert together with other metadata that needs to be stored. Therefore sending a smaller amount of inserts that each contain more data, compared to sending a larger amount of inserts that each contain less data, will reduce the number of writes required. We recommend inserting data in fairly large batches of at least 1,000 rows at a time. Further details here.
By default, inserts into ClickHouse are synchronous and idempotent if identical. For tables of the merge tree engine family, ClickHouse will, by default, automatically deduplicate inserts. This means inserts are tolerant in cases like the following:
- If the node receiving the data has issues, the insert query will time out (or get a more specific error) and not receive an acknowledgment.
- If the data got written by the node, but the acknowledgement can't be returned to the sender of the query because of network interruptions, the sender will either get a time-out or a network error.
From the collector's perspective, (1) and (2) can be hard to distinguish. However, in both cases, the unacknowledged insert can just immediately be retried. As long as the retried insert query contains the same data in the same order, ClickHouse will automatically ignore the retried insert if the (unacknowledged) original insert succeeded.
We recommend users use the batch processor shown in earlier configurations to satisfy the above. This ensures inserts are sent as consistent batches of rows satisfying the above requirements. If a collector is expected to have high throughput (events per second), and at least 5000 events can be sent in each insert, this is usually the only batching required in the pipeline. In this case the collector will flush batches before the batch processor's timeout is reached, ensuring the end-to-end latency of the pipeline remains low and batches are of a consistent size.
Use Asynchronous inserts
Typically, users are forced to send smaller batches when the throughput of a collector is low, and yet they still expect data to reach ClickHouse within a minimum end-to-end latency. In this case, small batches are sent when the timeout of the batch processor expires. This can cause problems and is when asynchronous inserts are required. This case typically arises when collectors in the agent role are configured to send directly to ClickHouse. Gateways, by acting as aggregators, can alleviate this problem - see "Scaling with Gateways".
If large batches cannot be guaranteed, users can delegate batching to ClickHouse using Asynchronous Inserts. With asynchronous inserts, data is inserted into a buffer first and then written to the database storage later or asynchronously respectively.
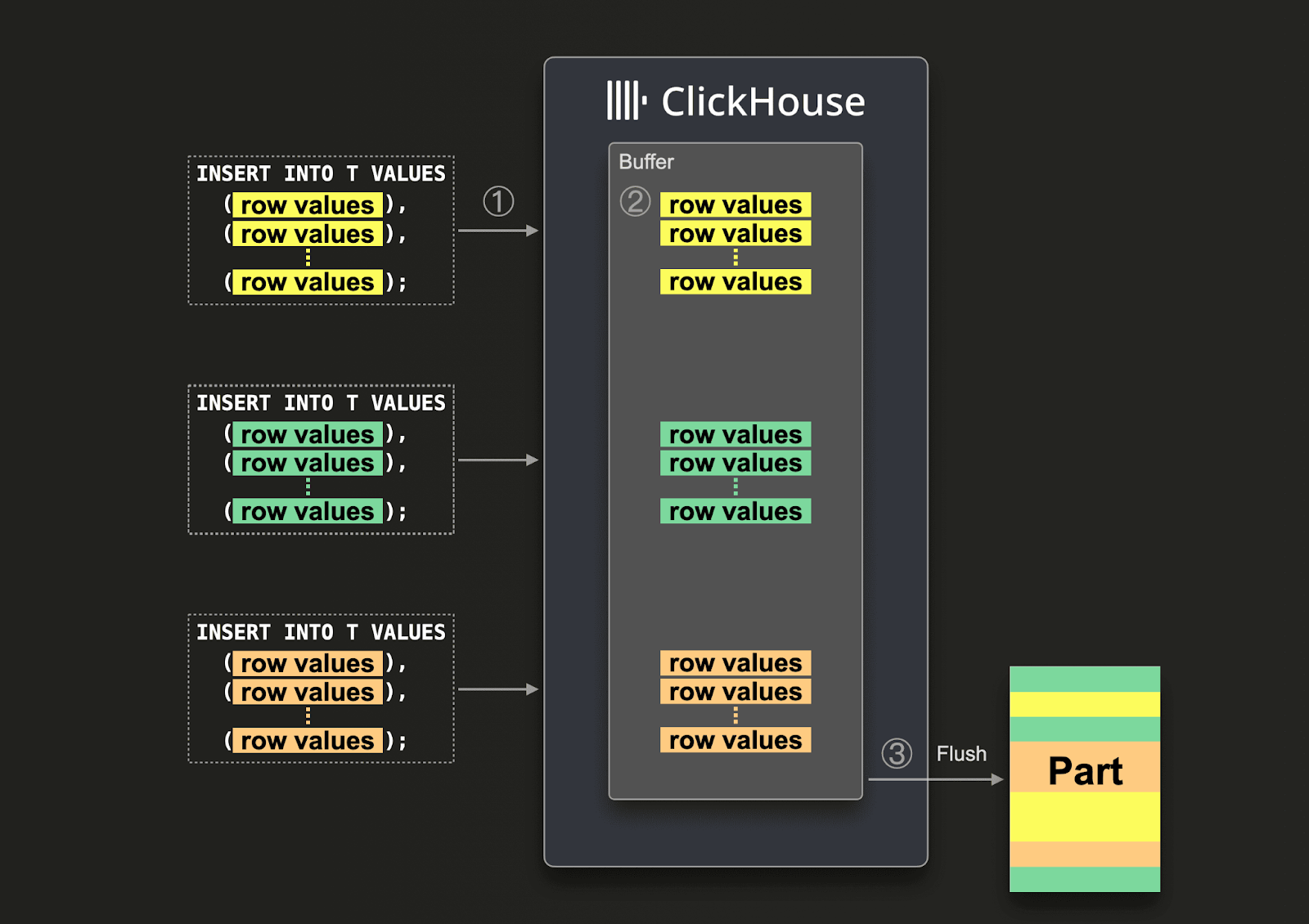
With enabled asynchronous inserts, when ClickHouse ① receives an insert query, the query's data is ② immediately written into an in-memory buffer first. When ③ the next buffer flush takes place, the buffer's data is sorted and written as a part to the database storage. Note, that the data is not searchable by queries before being flushed to the database storage; the buffer flush is configurable.
To enable asynchronous inserts for the collector, add async_insert=1 to the connection string. We recommend users use wait_for_async_insert=1 (the default) to get delivery guarantees - see here for further details.
Data from an async insert is inserted once the ClickHouse buffer is flushed. This occurs either after the async_insert_max_data_size is exceeded or after async_insert_busy_timeout_ms milliseconds since the first INSERT query. If the async_insert_stale_timeout_ms is set to a non-zero value, the data is inserted after async_insert_stale_timeout_ms milliseconds since the last query. Users can tune these settings to control the end-to-end latency of their pipeline. Further settings which can be used to tune buffer flushing are documented here. Generally, defaults are appropriate.
In cases where a low number of agents are in use, with low throughput but strict end-to-end latency requirements, adaptive asynchronous inserts may be useful. Generally, these are not applicable to high throughput Observability use cases, as seen with ClickHouse.
Finally, the previous deduplication behavior associated with synchronous inserts into ClickHouse is not enabled by default when using asynchronous inserts. If required, see the setting async_insert_deduplicate.
Full details on configuring this feature can be found here, with a deep dive here.
Deployment Architectures
Several deployment architectures are possible when using the OTel collector with Clickhouse. We describe each below and when it is likely applicable.
Agents only
In an agent only architecture, users deploy the OTel collector as agents to the edge. These receive traces from local applications (e.g. as a sidecar container) and collect logs from servers and Kubernetes nodes. In this mode, agents send their data directly to ClickHouse.
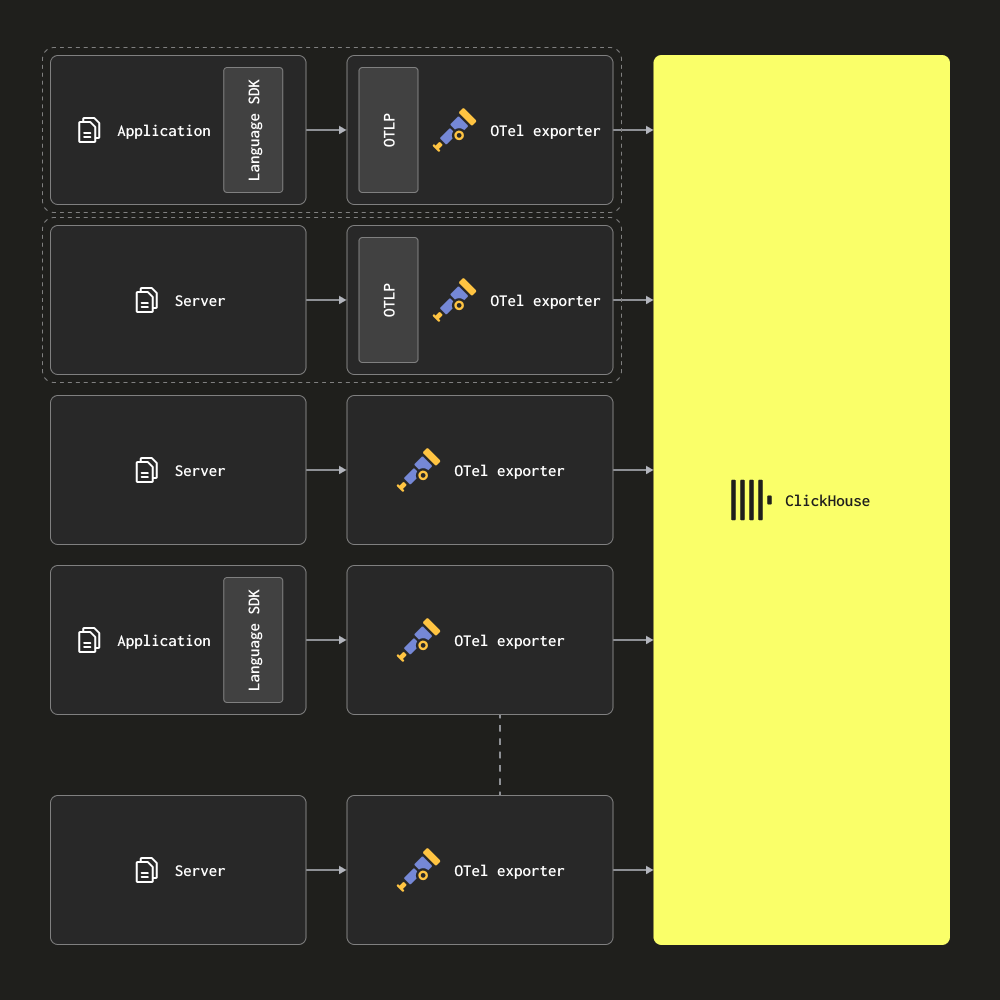
This architecture is appropriate for small to medium-sized deployments. Its principal advantage is it does not require additional hardware and keeps the total resource footprint of the ClickHouse observability solution minimal, with a simple mapping between applications and collectors.
Users should consider migrating to a Gateway-based architecture once the number of agents exceeds several hundred. This architecture has several disadvantages which make it challenging to scale:
- Connection scaling - Each agent will establish a connection to ClickHouse. While ClickHouse is capable of maintaining hundreds (if not thousands) of concurrent insert connections, this ultimately will become a limiting factor and make inserts less efficient - i.e. more resources will be used by ClickHouse maintaining connections. Using gateways minimizes the number of connections and makes inserts more efficient.
- Processing at the edge - Any transformations or event processing has to be performed at the edge or in ClickHouse in this architecture. As well as being restrictive this can either mean complex ClickHouse materialized views or pushing significant computation to the edge - where critical services may be impacted and resources scarce.
- Small batches and latencies - Agent collectors may individually collect very few events. This typically means they need to be configured to flush at a set interval to satisfy delivery SLAs. This can result in the collector sending small batches to ClickHouse. While a disadvantage, this can be mitigated with Asynchronous inserts - see "Optimizing inserts".
Scaling with Gateways
OTel collectors can be deployed as Gateway instances to address the above limitations. These provide a standalone service, typically per data center or per region. These receive events from applications (or other collectors in the agent role) via a single OTLP endpoint. Typically a set of gateway instances are deployed, with an out-of-the-box load balancer used to distribute the load amongst them.
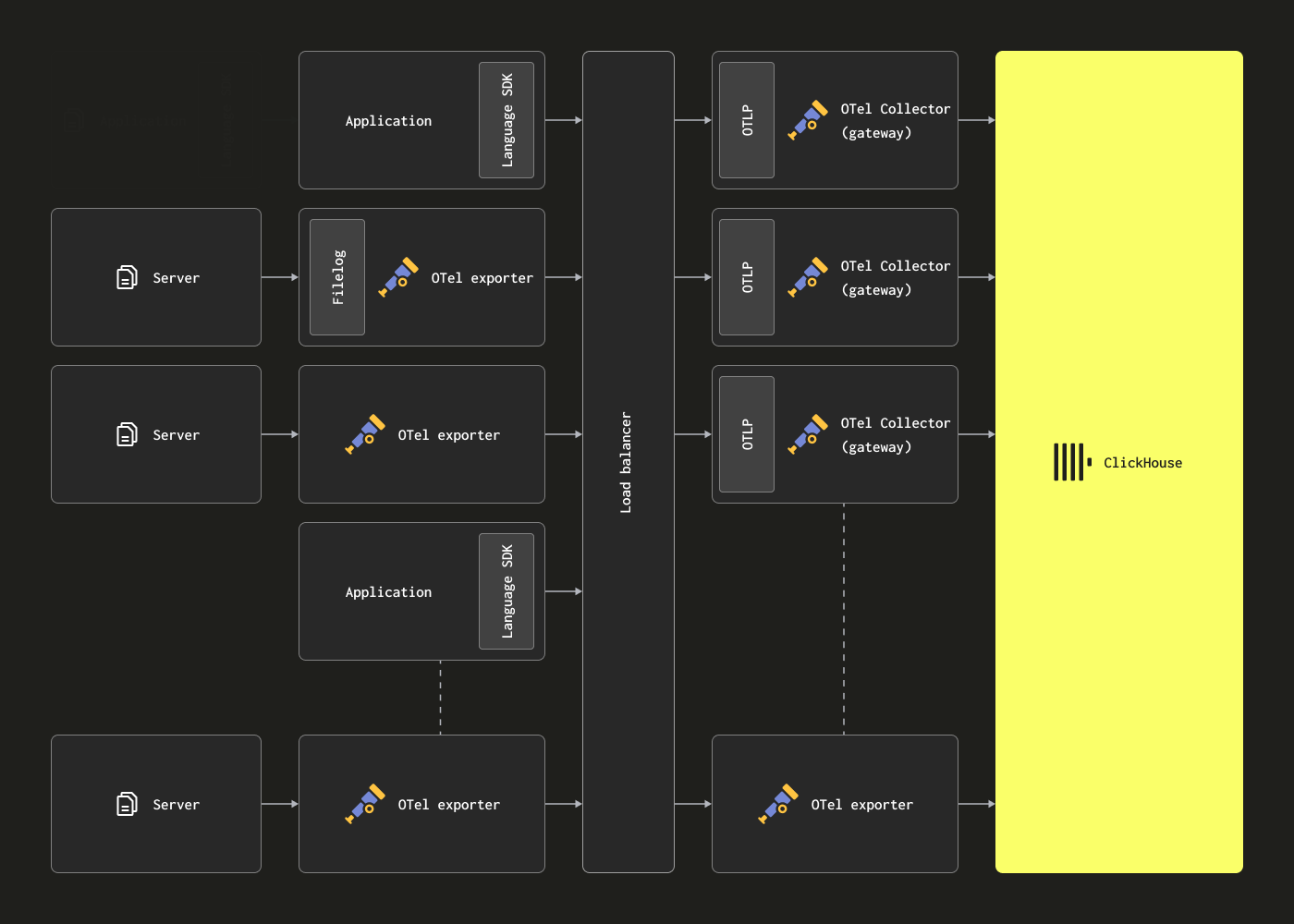
The objective of this architecture is to offload computationally intensive processing from the agents, thereby minimizing their resource usage. These gateways can perform transformation tasks that would otherwise need to be done by agents. Furthermore, by aggregating events from many agents, the gateways can ensure large batches are sent to ClickHouse - allowing efficient insertion. These gateway collectors can easily be scaled as more agents are added and event throughput increases. An example gateway configuration, with an associated agent config consuming the example structured log file, is shown below. Note the use of OTLP for communication between the agent and gateway.
receivers:
filelog:
include:
- /opt/data/logs/access-structured.log
start_at: beginning
operators:
- type: json_parser
timestamp:
parse_from: attributes.time_local
layout: '%Y-%m-%d %H:%M:%S'
processors:
batch:
timeout: 5s
send_batch_size: 1000
exporters:
otlp:
endpoint: localhost:4317
tls:
insecure: true # Set to false if you are using a secure connection
service:
telemetry:
metrics:
address: 0.0.0.0:9888 # Modified as 2 collectors running on same host
pipelines:
logs:
receivers: [filelog]
processors: [batch]
exporters: [otlp]
clickhouse-gateway-config.yaml
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
processors:
batch:
timeout: 5s
send_batch_size: 10000
exporters:
clickhouse:
endpoint: tcp://localhost:9000?dial_timeout=10s&compress=lz4
ttl: 96h
traces_table_name: otel_traces
logs_table_name: otel_logs
create_schema: true
timeout: 10s
database: default
sending_queue:
queue_size: 10000
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
service:
pipelines:
logs:
receivers: [otlp]
processors: [batch]
exporters: [clickhouse]
These configurations can be run with the following commands.
./otelcol-contrib --config clickhouse-gateway-config.yaml
./otelcol-contrib --config clickhouse-agent-config.yaml
The main disadvantage of this architecture is the associated cost and overhead of managing a set of collectors.
For an example of managing larger gateway-based architectures with associated learnings, we recommend this blog post.
Adding Kafka
Readers may notice the above architectures do not use Kafka as a message queue.
Using a Kafka queue as a message buffer is a popular design pattern seen in logging architectures and was popularized by the ELK stack. It provides a few benefits; principally, it helps provide stronger message delivery guarantees and helps deal with backpressure. Messages are sent from collection agents to Kafka and written to disk. In theory, a clustered Kafka instance should provide a high throughput message buffer since it incurs less computational overhead to write data linearly to disk than parse and process a message – in Elastic, for example, the tokenization and indexing incurs significant overhead. By moving data away from the agents, you also incur less risk of losing messages as a result of log rotation at the source. Finally, it offers some message reply and cross-region replication capabilities, which might be attractive for some use cases.
However, ClickHouse can handle inserting data very quickly - millions of rows per second on moderate hardware. Back pressure from ClickHouse is rare. Often, leveraging a Kafka queue means more architectural complexity and cost. If you can embrace the principle that logs do not need the same delivery guarantees as bank transactions and other mission-critical data, we recommend avoiding the complexity of Kafka.
However, if you require high delivery guarantees or the ability to replay data (potentially to multiple sources), Kafka can be a useful architectural addition.
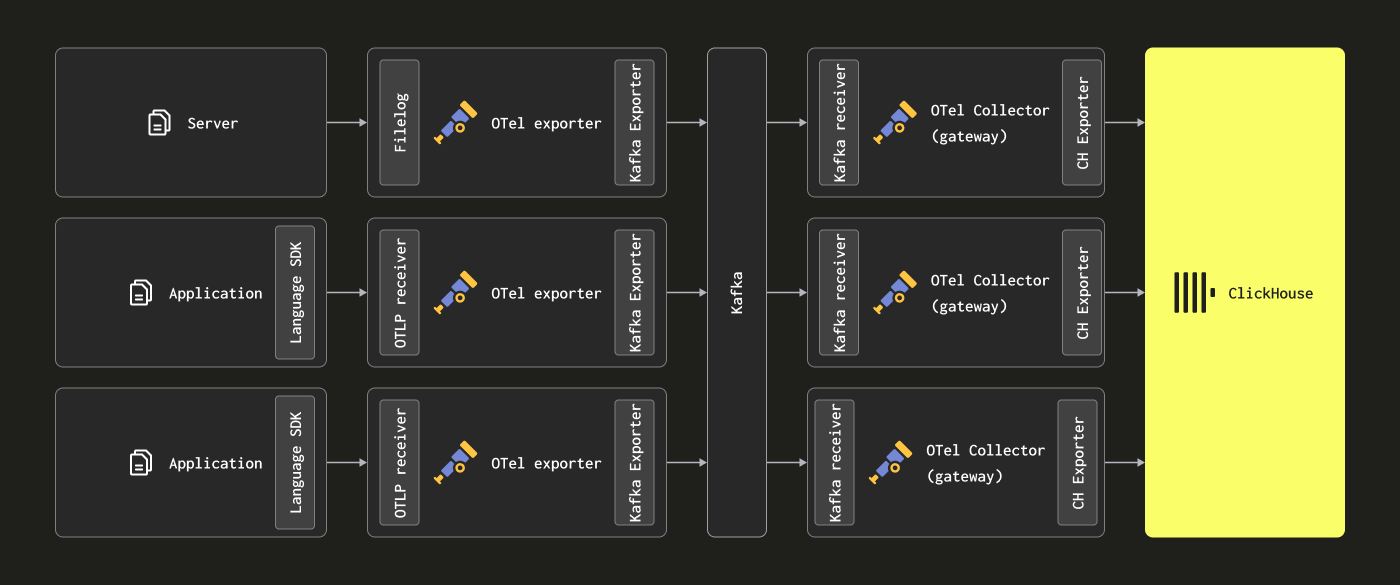
In this case, OTel agents can be configured to send data to Kafka via the Kafka exporter. Gateway instances, in turn, consume messages using the Kafka receiver. We recommend the Confluent and OTel documentation for further details.
Estimating resources
Resource requirements for the OTel collector will depend on the event throughput, the size of messages and amount of processing performed. The OpenTelemetry project maintains benchmarks users can use to estimate resource requirements.
In our experience, a gateway instance with 3 cores and 12GB of RAM can handle around 60k events per second. This assumes a minimal processing pipeline responsible for renaming fields and no regular expressions.
For agent instances responsible for shipping events to a gateway, and only setting the timestamp on the event, we recommend users size based on the anticipated logs per second. The following represent approximate numbers users can use as a starting point:
Logging rate Resources to collector agent 1k/second 0.2CPU, 0.2GiB 5k/second 0.5 CPU, 0.5GiB 10k/second 1 CPU, 1GiB
| Logging rate | Resources to collector agent |
|---|---|
| 1k/second | 0.2CPU, 0.2GiB |
| 5k/second | 0.5 CPU, 0.5GiB |
| 10k/second | 1 CPU, 1GiB |